Hi,
I am working with the ATLAS Open Data 2024r-pp release for a research project using the atlasopenmagic I have a few questions:
-
Could you confirm that the MC samples available in the 2024r-pp release via atlasopenmagic contain only BSM signal samples (Z’, W’, graviton, etc.) and no SM background MC (Z+jets, W+jets, tt̄, QCD multijet)?
-
Is there SM background MC available for Run 3 pp collision data anywhere in the ATLAS Open Data releases? If so, which release name or CERN record ID should I use to access it?
-
The 2024r-pp release metadata lists 374 datasets with DSIDs in the 301xxx range (e.g. 301204, 301209). Are these all BSM signal samples, and are there plans to release SM background MC for Run 3?
-
When parsing the 2024r-pp data files, I observe files with _mc_ in their filenames (DSIDs 37xxxxxx range). Could you clarify what physics processes these correspond to?
Thank you for your time and support.
Dear Maryna,
I suggest trying out the metadata tutorial:
https://opendata.atlas.cern/docs/13TeV25Doc/Concepts#accessing-metadata-new
That and our webpage’s documentation has most of the answers to your questions. In particular, though:
-
No, there are lots of SM background samples available. There’s a large metadata data table here you can also scroll through if you wish:
Monte Carlo Metadata | ATLAS Open Data
If you type, for example, ttbar in the search box, you will see several ttbar samples.
-
There is no Run 3 open data. None of the experiments provide Run 3 open data to the best of my knowledge.
-
As in #1, these are a few BSM signal samples and a large number of SM background samples. We do not expect to release Run 3 data or MC before about 2031.
-
Could you give me a particular example? Again, with either the metadata tutorial or the table on the website, you should be able to identify exactly what sample any DSID corresponds to.
Best,
Zach
Dear Zach,
Thank you for your response. I checked the metadata table and I can now see SM background samples listed there (ttbar, Z+jets, etc.), which clarifies my earlier confusion. However, I still have a question about what is actually accessible via atlasopenmagic in the 2024r-pp release.
When I parse all files returned by atlasopenmagic for this release, I observe:
2024r-pp (data): 55,620 files, 317 unique DSIDs — all in the 370xxxxx range
2024r-pp_mc: 14,581 files, 550 unique DSIDs across ranges: 371xxxxx, 372xxxxx, 373xxxxx, 375xxxxx–378xxxxx, 381xxxxx–383xxxxx, 386xxxxx–388xxxxx
My question is whether these 37xxxxxxx-range DSIDs include SM background processes (Z+jets, W+jets, tt̄, diboson, etc.), or only BSM signal samples. The metadata table on the website lists DSIDs in the 301xxxxx range for SM backgrounds — I don’t see those in what atlasopenmagic returns for 2024r-pp_mc. Could you point me to a specific DSID (e.g. a Z+jets or tt̄ sample) that should be accessible via atlasopenmagic in this release, so I can verify I’m not missing anything?
Thank you again for your help.
Best regards,
Maryna
Hi @maboryso ,
410470 is our standard ttbar sample, for example. 700320, 700321, 700322 (which have to be combined) are our standard Z>ee samples. All those should be accessible via atlasopenmagic.
The DSID ranges are not really well structured. They’re unique, and we try to keep like samples together (so e.g. Z>ee and Z>mm are next to each other), but unfortunately it’s not as simple as “All SM backgrounds are in this range.”
Best,
Zach
Dear Zach, Thank you for your answers. I have follow-up questions.
The documentation states that the MC samples are tailored to represent double the luminosity of the corresponding data (72 fb⁻¹ equivalent vs. 36 fb⁻¹ for data). However, when I parse and process both the data and MC files from the release, I observe roughly 10× fewer events in MC than in data for the same final state.
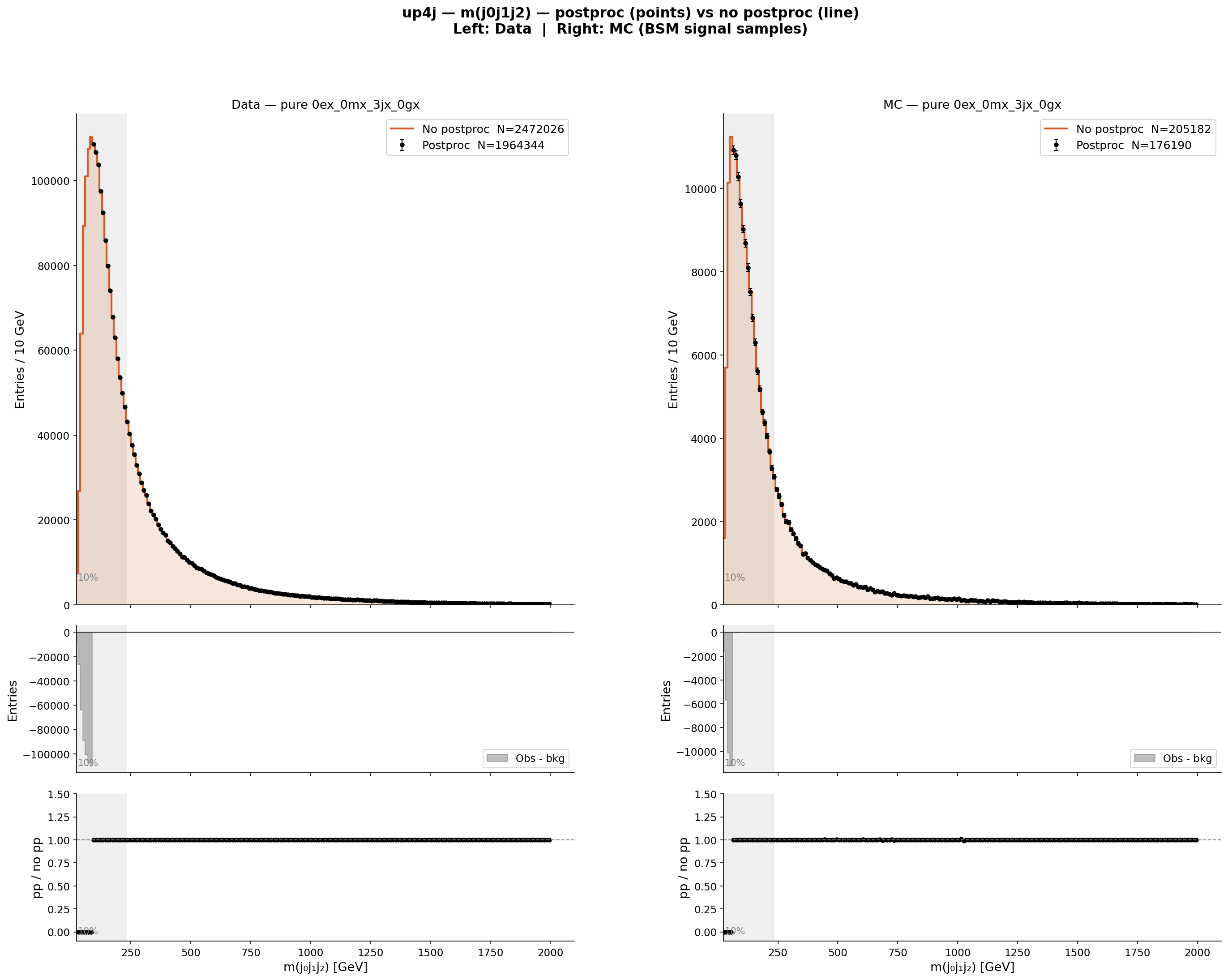
As a concrete example, for the final state 0ex_0mx_3jx_0gx (pure 3-jet, no leptons), the invariant mass distribution m(j0j1j2) shows:
- Data: N = 2,472,026 events (no post-processing) / 1,964,344 (with post-processing)
- MC: N = 205,182 events (no post-processing) / 176,190 (with post-processing)
This is approximately a 12× deficit in MC relative to data, which is the opposite of what the “double luminosity” statement suggests.
My questions:
- Should MC events be weighted by their cross-section and the luminosity ratio (data_lumi / mc_lumi = 36/72 = 0.5) before comparing to data? If so, where can I find the per-sample cross-sections and filter efficiencies needed to compute these weights?
- Is the
atlasopenmagic metadata sufficient to retrieve cross-sections (e.g. via atom.get_metadata(dsid)['crossSection_pb']), or is there a recommended separate source?
- For the
2024r-pp MC, I observe that the MC event count is much lower than data even before any weighting, which makes me think I may not have all relevant SM background samples were released. Is it correct?
Thank you for your time.
Best regards, Maryna
Hi @maboryso ,
The goal is something like double the data, with a minimum of 10k events and a maximum of 10M events for each of the research samples (e.g. for a VERY large cross section process, we don’t have the resources to release double the luminosity of the data). The jet samples in particular are heavily filtered and hit the maximum. I’m a little surprised you have so much more data than MC, though. Which MC samples exactly do you include?
Yes, you should always weight the samples using their cross section, filter efficiency, k-factor, and sum of weights. This is not simply a factor of 0.5. The metadata package I mentioned above has all the necessary information to do so. You can see a number of examples in the sample analyses that we’ve released.
Best,
Zach
Dear Zach, thank you for your answer.
I included all available MC files from the 2024r-pp release.
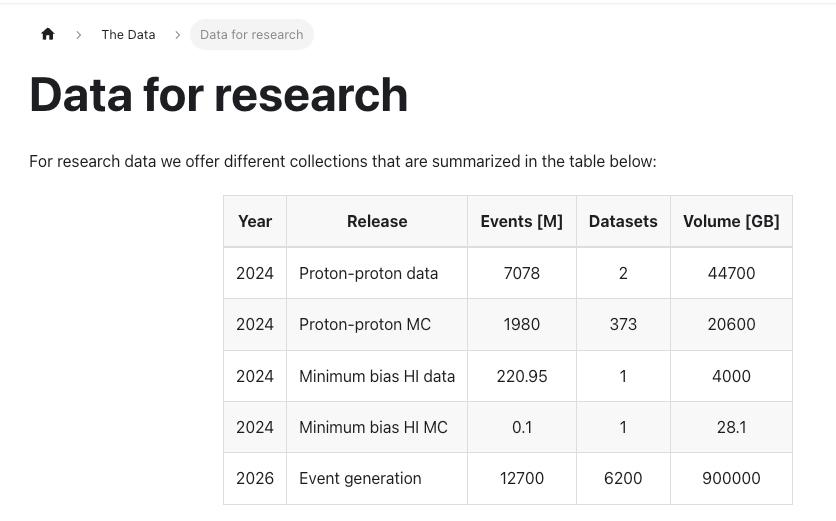
As I mentioned, I downloaded the 2024r-pp release with all 70,201 files.
When I parse all files returned by atlasopenmagic for this release, I observe:
- data: 55,620 files
- mc: 14,581 files
So MC roughly is 1/3 of the data. This can also be seen in the table on the OpenData website. The number of released N events is also 1/3. So, I assume this is correct, don’t I?
Kind regards,
Maryna
Hi @maboryso ,
Ah wow! Very few folks just run on all the MC — I’m surprised (but happy) to hear that you have the computing power for that. There are a few things to check on, then:
- For sure, you’ll need to use the cross section, k-factor, filter efficiency, luminosity, and sum of weights for each of the MC samples to get their individual weights right
- Data are taken with a variety of triggers. For a ‘simple’ 3-jet selection like the one you described, it’s not obvious to me what triggers will be most appropriate. In all likelihood, you’ll want to require some specific trigger firing to avoid bias. You can see how we do that in the standard PhysLiteToOpenData package here.
- Usually you will need to make some selections to ensure that the trigger is fully efficient. If, for example, the trigger you require is
trigPassed_HLT_3j175, you will want to require at least 3 jets above, say, 225 GeV to ensure no further bias in the selection of data. You can make a distribution of the number of events passing that selection as a function of the 3rd leading jet pT to see if the trigger selection is doing what’s expected (you could start the distribution at 150 GeV to really see the “turn on” of the trigger).
Once you have those three things sorted out, then I would try re-making the figures. There might be some residual differences between data and MC due to your vetos (of photons in particular); if that looks like an issue we can talk about a “veto scale factor”. But already those steps should get things into much better shape, I expect.
Best,
Zach