Thanks for the question! Each experiment has some basic introductory material that might provide some of what you’re describing. Here’s CMS’s guide:
Here’s ATLAS’s:
The data we release are measured, and normally have particle momenta. The mass of a particle can actually be quite hard to measure. Momentum is easier to work with than velocity when we get very close to the speed of light, and energy is connected to mass and momentum. Almost all of the particles that come out of our collisions that we measure have velocities well above 0.9c; the particles that we collide all have velocities far, far above 0.9c.
By XL, do you really mean Microsoft Excel, like a spreadsheet? If so, you might want to start with something that’s relatively set up for you, like the notebooks we provide:
Those are ATLAS’s; CMS has something very similar. Those allow you to do everything in a web browser so you don’t need to download data or install software to get started. With the ‘full’ datasets, we tend to provide them in formats that can be read with ROOT (http://root.cern), and we often provide tools for translating them into other formats or reading them with other tools (like uproot and numpy in python, as you’ll see in the notebooks linked above).
I am particularly interested in how the energy per proton is determined for speeds much greater than 0.9999c. While I work through those files could I also ask:
For runs at .999999991c how is the energy per proton actually determined to be at 7TeV?
Is this a function of the energy used to accelerate the particle in some way: for example, given that the rest mass of a proton is known and I assume that the velocity is also precisely known (i.e. for timing to accelerate at RF Cavities), so is the Energy per proton actually calculated using the relativistic equation (ymc^2). Or, is the 7TeV really measured somehow before collision?
Energy and velocity are deeply related, and we have relativity to connect the two, yes. In practice we have a few different ways to measure the energy of the beam. There’s a paper on the subject here:
Some of it’s pretty technical, but I hope you’ll be able to get the right idea, which is that the main measurement comes actually by measuring the magnetic field that the protons are subject to and then doing some math to understand how fast they need to be going (how much momentum they need to have) in order to be in orbit in that magnetic field.
There is not a ‘direct’ measurement of the proton momentum before a collision, nope.
Edit: in case it’s useful, there’s also a talk on the same subject here:
Thank you once again for replying with those references. I will be able to use them!
After some further digging the plan is to use notebook and write the ROOT commands to simply sum the total measured energy for all Jets produced for a given collision run. I have not used ROOT before, so now working on the commands for that.
Assuming that each collision run consists of the same number protons and have similar collision rates, will then measure the total Jet energy sum for several TeV proton collision runs (7Tev, 8Tev, 9TeV, 13 TeV, etc)
This format is only provided for 13 TeV collisions except in our outreach samples. I can give more information later if you’re interested in getting some NanoAOD-like files for 7 and 8 TeV.
Our 2024 workshop has exercises to help you set up a computing environment and learn how to interact with NanoAOD. In particular you might check out:
the Docker Containers lesson up through Exercise 2, which is a minimal example of opening a NanoAOD file and accessing an array of data.
the Open Data Analysis in C++ and Python lesson – this is written with CMS examples but is a general intro to ROOT and HEP python libraries.
the Physics Objects “pre-learning” lesson, which goes through all the different types of particles we store and which variables are available for them.
Your analysis scenario:
For the several TeV proton collision runs (7Tev, 8Tev, 9TeV, 13 TeV, etc) obtain the following:
Equivalence Assumption: Each p-p collision run (i.e. 7Tev, 8Tev, 9Tev, 13 TeV, etc) consists of the same number of protons in each run, and each run also has a similar collision rate; i.e. equivalent in both these parameters.
This is probably not a very strong assumption. Those conditions have evolved over time. What I would do is use a “number of interactions” variable to try and control for similar conditions. The number of simultaneous collisions isn’t directly related to the number of protons in the bunch, but it strongly affects the total energy deposited in the detector. In a CMS NanoAOD file you would use PV_npvs as this variable. You can see distributions of the CMS “pileup” profile for all of the different LHC runs here: https://cmslumi.web.cern.ch/publicplots/pileup_allYears.png
Determine the total Energy deposited (as measured by Calorimeters) of the collision debris:
In CMS NanoAOD, a useful set of variables would be *MET_sumEt. This is the scalar sum of the transverse-plane energy of everything. There are several versions of this variable that correspond to different calculations (e.g. one is CaloMET_sumEt and that would use only calorimeters).
If I’m understanding your goals correctly, I would probably start by trying to make distributions of some sumEt variables across different collision energies for events in common pileup ranges.
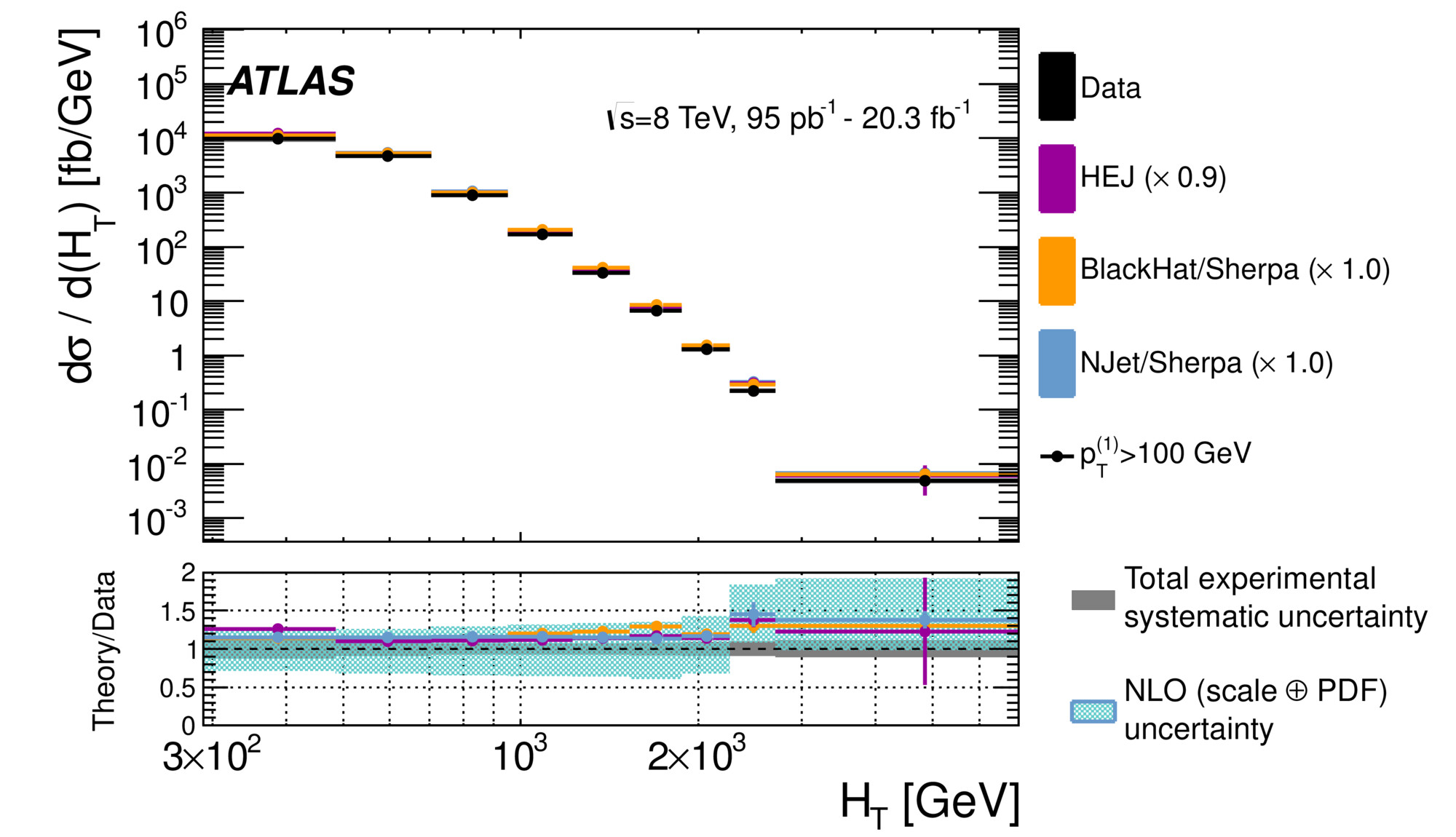
The variable you’re describing is called H_T in ATLAS (often S_T in CMS), and the plots look something like this when summing the jets’ transverse momenta:
We don’t usually sum the energy itself for a variety of reasons, most importantly that the detector does not measure very well particles that continue down the beam line (in the direction of one of the original protons). Instead, we sum transverse momenta (the component of the momentum transverse to the beam line).
At the minimum, I need at least two data sets for measured Energy at two different TeV runs for what I am trying to achieve. If those measurements exits already and are comparable with two TeV runs (i.e. proton number and collision rate), then I could possibly use that! They do not have to be an exact match, as long as i know the difference I can just adjust the obseved results proportionally for my needs.
I just need a single 7TeV run file and a single 8TeV run file (that is that same number of collision events for comparison). I will then extract the MET_sumEt and 'CaloMET_sumEt`variables for those files along with a similar (number of events) 13TeV run file. That is all I actually need. Those 2 variables from one 7Tev, 8TeV, and 13TeV file.
Have been trying to get all the tools up and running for the past 2 days and still just getting ROOT errors [EDIT: Finally got ROOT going on day 3 so hopefully all good to go]. So I plan to search the 3 run files for those two attributes and just extract them manually.
I noticed the NanoAOD files are around 5 gig, so this should be manageable.
I have a further questions that I was hoping you could help with. The 7TeV and 8Tev root files both have the two fields you mentioned (MET_sumEt and CaloMET_sumEt) - great!
However the 13Tev root files do not have those fields. Could you possibly confirm what I have done below is correct?
To get the sum of all energy in the detector for 13TeV (i.e. same as MET_sumEt), I have summed all energy measurement fields, these are:
nelectron_e
electron_e
nfatjet_e
fatjet_e
njet_e
jet_e
met_e
nmuon_e
muon_e
nphoton_e
ohoton_e
ntau_e
tau_e
Regards
Chris
P.S. I will be looking at the Atlas data next and will probably have a similar question for Zach shortly…
I’m realizing now my previous reply bounced… here it was:
Hi Chris,
Yes, we have software available for the 2011 and 2012 data that produces a file very similar to NanoAOD.
I would suggest searching for our 2016 “JetHT” NanoAOD dataset and see if you can extract the data you want, or if there are questions. These events would all pass some type of jet trigger, and the other datasets would have different shared characteristics (e.g. all passing a muon trigger, photon trigger…)
If you can let me know how many events you are interested in studying and which particular variables want that would be good. Over the next ~week I can make sure the software can provide those variables and then we could chat to see about processing a few 7 TeV and 8 TeV files.
This file does have the sumEt values I need, however something does not seem right. There are several more sumEt values in that file and those entries do not add up to the total MET_sumEt value. These additional fields are as follows:
ChsMET_sumET
RawMET_sumET
RawPuppiMET_sumEt
TkMET_sumEt
However, if I compare to other 13TeV files I have used so far, the mean total energy detected is around 20,000 - 25,000, which is what I was expecting. If I sum those 4 fields above, it gets into that range and looks correct, however that does not equate to the value given in MET_sumEt. What am I missing?
I do have another question, what is the value of these all readings GeV?
Ok, those “Run 1 NanoAOD-like” files should work, though I would choose a 2011 file for 7 TeV since it had better conditions for analysis than 2010.
(List of all of them: CERN Open Data Portal)
NanoAOD Run 1 was developed a little earlier than the 2016 NanoAOD files that we have released, so some differences between file contents are expected.
In general, the various sumEt variables are not intended to be summed. The ones you have listed here are definitely not subsets, they more represent different computation methods with different physics object corrections.
If you want to use a value with typical CMS corrections included (e.g. the jet energy corrections) then I would suggest MET_sumEt. That MET collection is based on our particle flow reconstruction of the various physics objects and at least in 2016 NanoAOD should have the jet energy corrections included (I will need to check about the Run 1 files in that regard…)
If you would like a more basic value, I’d suggest RawMET_sumEt. As the name suggests, this calculation is “raw” and doesn’t include any corrections for the physics objects. If that would be better for your analysis, we can work on adapting the Run 1 NanoAOD-like producer tool and reprocessing a few files.
Ok, those “Run 1 NanoAOD-like” files should work, though I would choose a 2011 file for 7 TeV since it had better conditions for analysis than 2010.
I will download a few 2011 files in that case and look at the values.
Would just like to confirm the mean value shown in individual root files is simply the total recorded energy divided by the number of entries in that file. I checked that myself and that seems to be what mean represents.
In general, the various sumEt variables are not intended to be summed. The ones you have listed here are definitely not subsets, they more represent different computation methods with different physics object corrections
Ok got it …after I posted the message I thought that may have been the case.
If you would like a more basic value, I’d suggest RawMET_sumEt. As the name suggests, this calculation is “raw” and doesn’t include any corrections for the physics objects. If that would be better for your analysis, we can work on adapting the Run 1 NanoAOD-like producer tool and reprocessing a few files.
I cant seem to find the RawMet values in those earlier 7TeV and 8Tev. This may be due to the Root object browser I am using. In any case, for the time being the the current MET and CaloMet values look to be good for my analysis; (no need to re-purpose just yet).
Thank you once again for you help on these files… I might need to come back with a few more questions as I dig in further.
I have analysed quite a few files, however it looks like the derived format are a bit too filtered for what I am trying to look for (and the Raw_Met fields do not seem to present in the 7TeV and 8TeV NanoAOD files). So I will now take a look at the primary datasets.
I do have two questions for you if that is ok:
I am trying to find a data dictionary (data field descriptions) of all the data items in the CMS primary data root file. The best that I can find is links such as these Link 1, Link 2, Link 3; however the data fields described do not match the fields in the data sets. I can deduce most of the fields, but would prefer to use a precise data format description. I noticed Atlas have a great data dictionary here, and was hoping to find something similar for CMS.
You had mentioned previously above to use the 2011 7TeV datasets rather than the 2010 7TeV. Is there any particular reason for that other than improved pile-up?
We might have reached the point where it’s easiest to Zoom and chat. You can send mail to cms-dpoa-coordinators@cern.ch and we can set something up.
What do you mean by “too filtered”? Do you mean that you are looking for particular observables that you don’t find in the Run 1 NanoAOD-like files, or do you mean that these datasets where each event has muons don’t seem appropriate? We had already concluded that RawMET is not in those files, so if you’ve decided you want that variable we will definitely have to go up a level.
ATLAS’s dictionary is for a file type similar to NanoAOD. For 2016 NanoAOD you can find that type of dictionary at the “Variable List” link under “Dataset Semantics” in any NanoAOD record (ex: /JetHT/Run2016H-UL2016_MiniAODv2_NanoAODv9-v1/NANOAOD | CERN Open Data Portal). The Run 1 NanoAOD-like files follow an extremely similar variable list – there will necessarily be some Run 1 / Run 2 differences, but hopefully easier to infer or of course we can help with any particular questions.
However, for our Run 1 AOD datasets there is no simple way to list “all the fields”, because the ROOT TTrees do not store data in basic C++ types. The “collections” are all custom C++ classes defined by CMS, such as a reco::muon. The Link 2 you found is a great reference for which collections are in AOD. If you walk through our Getting Started with CMS AOD Data page you will learn about the edmDumpEventContent command that allows you to list all the C++ collections stored in the data file. Interacting with this more complex data type is very powerful but requires the CMS software environment via a docker container or virtual machine.
If you are interested in adding more observables to a file that has the NanoAOD type structure, that can be done by adapting the Run 1 NanoAOD producer tool, and processing some AOD data. I can help you set that up, make the edits, and figure out the best computing options for whatever data volume you’re interested in processing.
The 2010 dataset is very small, and is best suited for studying low-pileup phenomena. I believe you are most interested in matching pileup scenarios across the years, so 2011 data will give you better statistics for that type of study.
I am now working my way through the Atlas 13Tev datasets and just was hoping to clarify something.
The PhysLite data format defines variables for transverse momentum (.pt), mass (.m), and energy (.e). However, when I examine the root files using the root browser I can see entries for mass and pt, but no entries for energy ending in “.e”. Is the energy variable viewable from the root browser or perhaps renamed with an alias variable suffix?
In order to keep the data files small, we try to avoid storing duplicate information. With m, pt, eta, and phi you can make a momentum 4-vector with which you can calculate E (and any other kinematic variables you want). There are examples of doing so in the notebooks examples we provide.
Generally speaking, transverse quantities are the ones of interest at colliders like ours, since the momentum of the colliding particles along the beam axis is not known. With the 4-vector, you can also get transverse energy if you wish.
Thank you for responding…! For my project I actually need the measured energy by the detector (rather than derived values from relativistic formula)… is there any chance that the Atlas detector does measure particle energy and store this away somewhere…?
For my project, at minimum I need at least two calorimeter measured variables and was hoping for pt and energy. I assume mass is not actually measured and the datasets are just populated with invariant mass for known particles.

{kind=link}