I am analyzing RUNA/B 2010 CMS OD using the analysis code from the example code to produce the di-muon spectrum from a CMS 2010 primary dataset.
The portal page with data indicates the number of events 51802592 - RunA, and 32376291 - RunB.
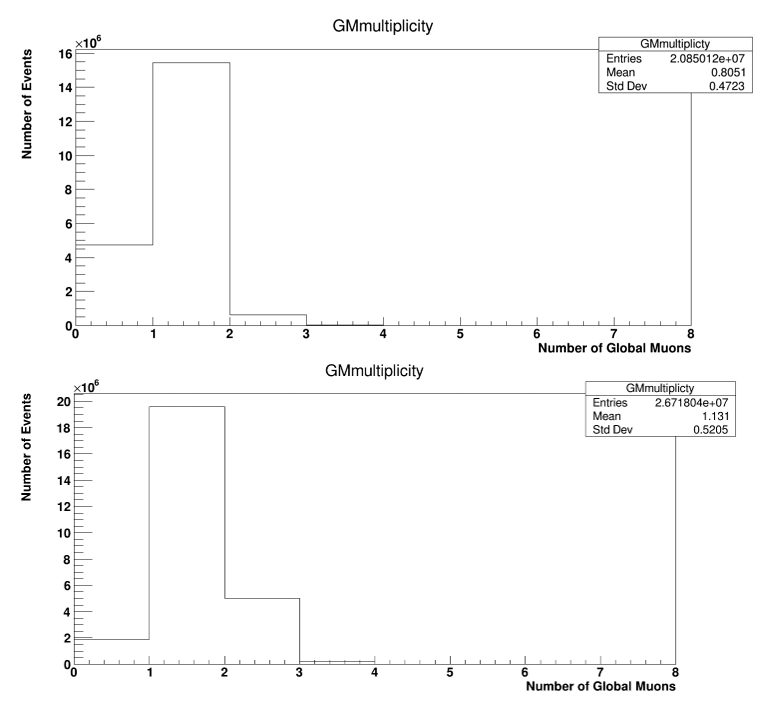
In my results in Figures 1 and 2, the number of events for RunA is 20800000, and RunB is 26700000.
I would be grateful if you could explain what I could have been wrong about, or what is the reason for the absence of 46% of events.
Thanks
Thanks for your interest in CMS open data! The difference comes from the fact that the dataset contains events selected by trigger algorithms. You can see their names listed for each collision dataset. The trigger algorithms are run online, at the time of data taking, and use quick estimates to detect a possible presence of a physics object, such as muons. These algorithms are different from the final reconstruction and therefore, passing the trigger selection does not guarantee that the event contains two muons that can be reconstructed as “global muon” i.e. with matching signal the inner tracker and the muon system.
As I understand it, you say that the decrease in events is due to selection in the analysis. In the file DemoAnalyzer.cc filling in the histogram “Gmultupliciti” stands before the selection by ValidHits , PixelHits and normChi2, and displays the number of tracks. As I understand it, it should correspond to the number that is stated on the data set page.
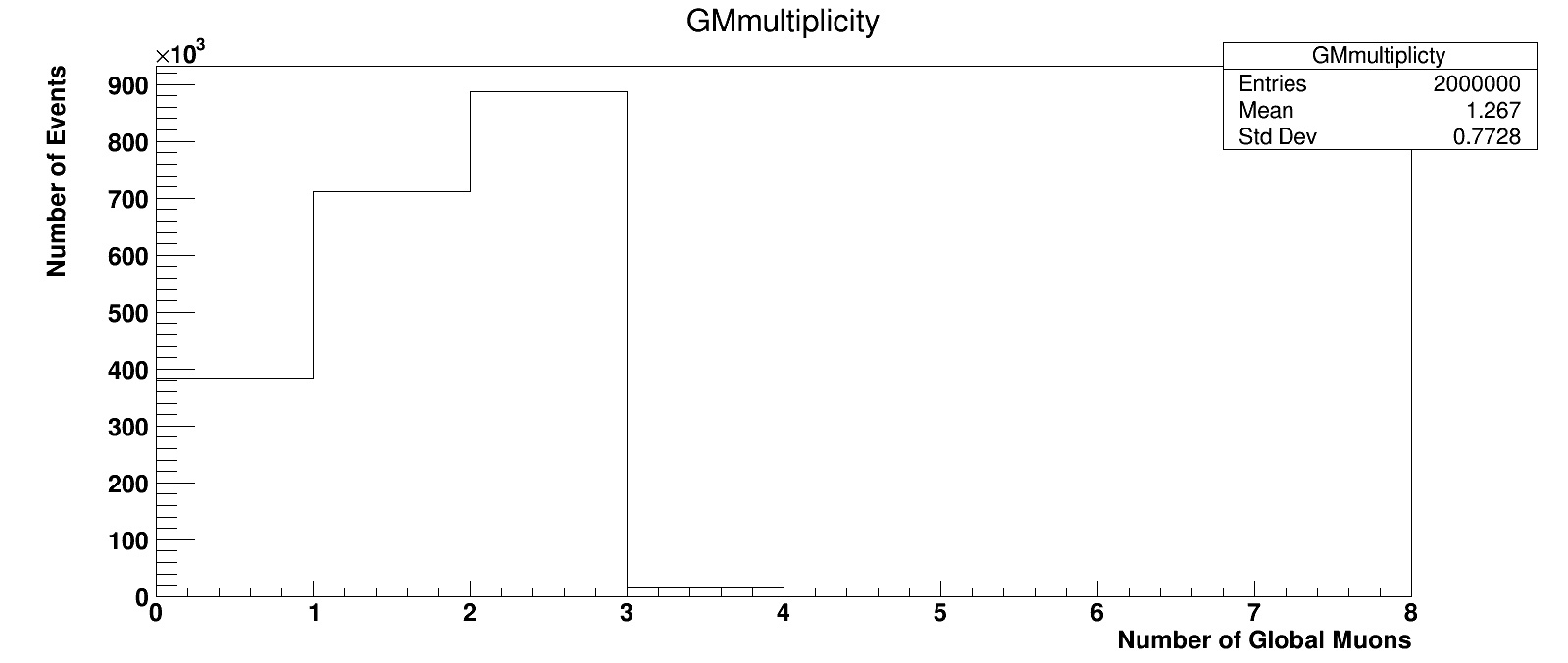
I analyzed the data of MC Drell-Yan for 2010, and got a number (2000000) corresponding to what is written on the CMS OD page ,
Note that the collision datasets contain data from real collisions and the data are directed to “primary” datasets such as /Mu/Run2010A-Apr21ReReco-v1/AOD based on the different trigger algorithms. Many of these triggers do not require the presence of two muons. And even if there are two muons in the event, it may be that they do not qualify as “Global Muons” in the reconstruction phase.
For simulated data, instead, e.g. for the DY sample that you mentioned, events are actually generated so that they always contain 2 muons.
Looking more carefully at your plot, now I see the point. There’s indeed a 0 bin as well, so if you run over the full dataset you would indeed expect to see all entries if there’s no further filtering before that point in the code. Can you point to the exact code and configuration that you run so we can look more in detail?
I used the analysis file DemoAnalyzer.cc and the configuration file demoanalyzer_cfg.py from “Example code to produce the di-muon spectrum from a CMS 2010 primary dataset”. CERN Open Data Portal
Thanks! Do you run it over all file index files (line 46 in the configuration file)?
The example configuration has only one but there are six of them in this data record.
There is also the filtering of the certified events (line 28 of the configuration file), which reduces the event count slightly but does not count for such a reduction.
Hi! I’ve now verified the event numbers for both of those datasets and they are as displayed on the respective portal records, i.e. 51802592 and 32376291.
Now cross-checking: do your listing have a total of 1588 files for the RunA Mu dataset and 2979 for the RunB Mu dataset? Do you have a way to verify that the job(s) run over all these files?
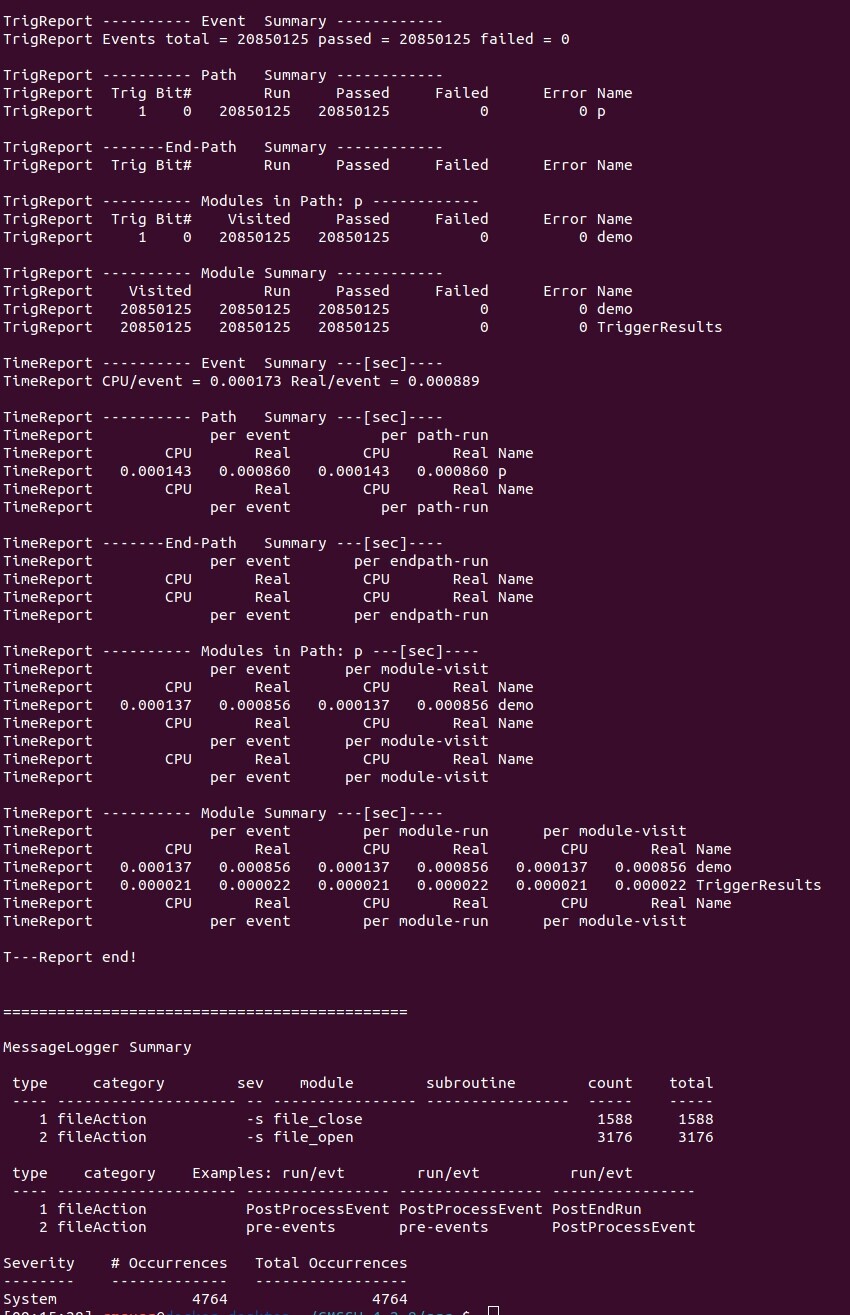
So far I can show the RunA analysis logs. I noticed that starting from the file "root://es public.cern.ch//eos/opendata/cms/Run2010A/Mu/AOD/Apr21ReReco-v1/0000/905E2912-4770-E011-972E-0017A4771028.root "there was no analysis of the events.
How can I to verify that the job(s) run over all these files?
Thanks! I was able to read that file without problems.
Can you confirm that you have set the number of events to -1 so that all events are read?
For such a large-scale production, you would need to modify the logging yourself in a way that you can follow the progress and be able to see if there are eventual error messages.
There is some advice on logging in the recent Open data workshop tutorial but mind that the CMSSW version used in it is different from that needed for 2010 data.
To be honest, I didn’t understand what I needed to change in MessageLogger to find errors. However, I noticed in the logs that some lines from Fille_index are not executed. As an example, I give a part of the RunA index_0020 analysis. If you have any suggestions what might be behind this, then I would be glad to hear them.